Core concepts in reproducibility
Overview
Teaching: 20 min
Exercises: 10 minQuestions
What is the reproducibility crisis?
How can working Openly and reproducibly help me?
What are the key reasons for irreproducible research?
How can we solve these key problems in our research?
Objectives
Have an overview of issues surrounding the reproducibility crisis and current ways to avoid those pitfalls.
Be aware of the tools and practices that are used in your area of research and how they may contribute to the reproducibility crisis.
Motivation
Today we’re going to be building towards a reproducible and open work-flow for research
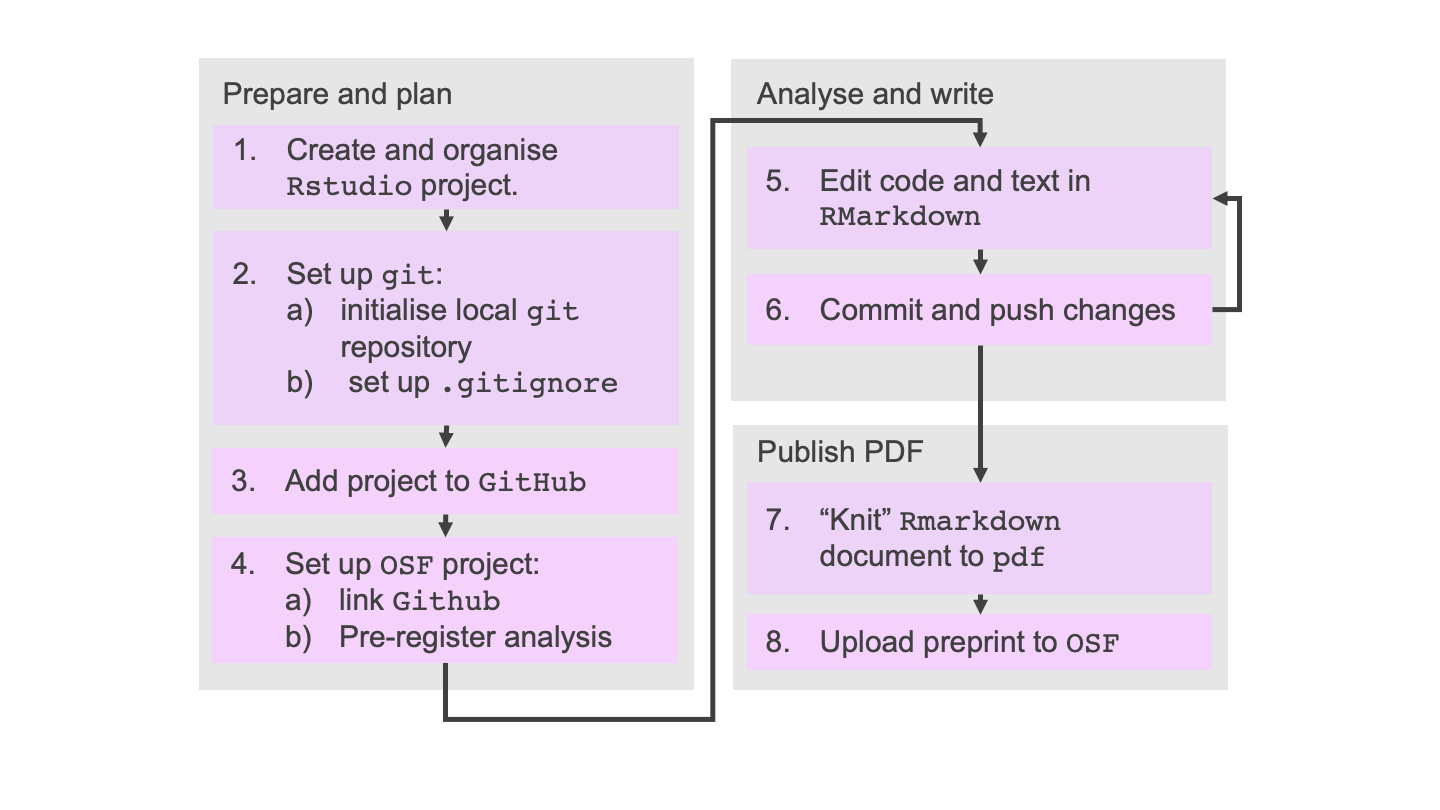 I’d like to begin by letting you know why it’s important and exactly which problems we’re trying to solve with this work flow.
I’d like to begin by letting you know why it’s important and exactly which problems we’re trying to solve with this work flow.
It’s important that we can trust the results of research because we rely on those results to inform us. We make policies and laws, and choose which avenues of our own research to explore. If research is untrustworthy, that could result in anything from wasting time and money, to causing a PhD student distress, or even costing lives (by influencing policy or drug availability for example).
Aside from the important benefits for society, we also want others to trust our research as it’s connected to our reputation, and our success in our future careers.
What is reproducibility?
The most basic definition of reproducibility is: a research result is reproducible if you can get the same result when you do the research again. Sometimes it’s useful to go one step further and distinguish between different types of reproducible research.
The matrix below (from The Turing Way) gives a useful set of definitions:
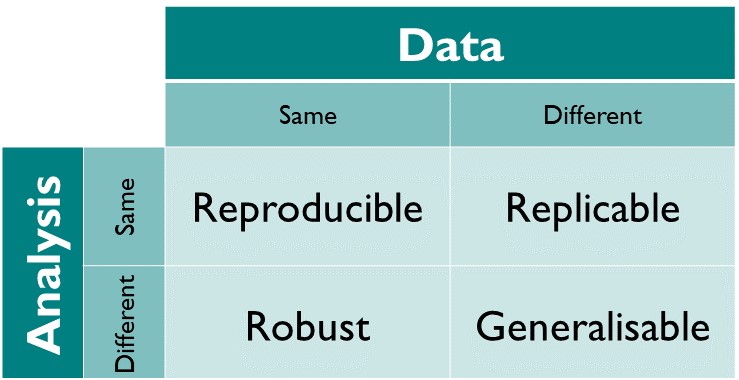
- Results are reproducible if we get the same result when we do the research again using the same analysis, on the same data.
- Results are replicable if we get the same result when we do the research again using the same analysis, on different (newly collected) data.
- Results are robust if we get the same result when we do the research again using different analysis, on the same data.
- Results are generalisable if we get the same result when we do the research again using a different analysis, on different (newly collected) data.
Discussion
In pairs discuss the following.
How often do you think:
- research in your area would be reproducible, if you had access to the exact data and analyses?
- research in your area would be replicable, if you had access to the exact data and analyses?
- research in your area provides access to the exact data and analyses? (3 minutes total)
The reproducibility crisis
The reproducibility crisis is a recent event in science, where scientific results were found to replicate much less than scientists had assumed or hoped that they would.
Less than 40% of replications of well-known Psychology studies were found to reproduce (have significant results):
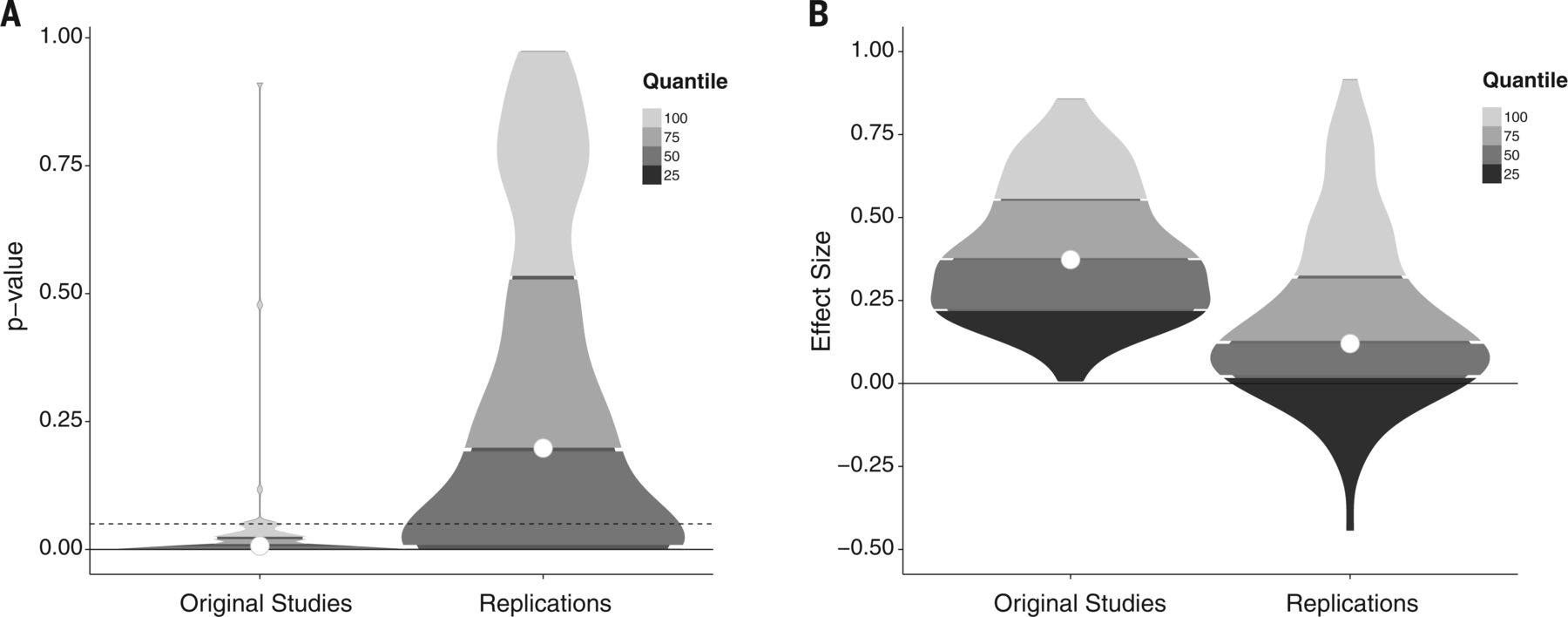 P-values in the original studies were constrained between 0 and just above 0.05, but in the replications, p-values ranged from 0 to 1 (with less than 40% being less than 0.05). Effect sizes were noticably lower, too.
P-values in the original studies were constrained between 0 and just above 0.05, but in the replications, p-values ranged from 0 to 1 (with less than 40% being less than 0.05). Effect sizes were noticably lower, too.
Similar results were found in Cancer Biology (where only 11% of results replicated). Begley, C. Glenn, and Lee M. Ellis. “Drug development: Raise standards for preclinical cancer research.” Nature 483.7391 (2012): 531.
Not only that, but most researchers agree that there is a problem, and most have failed to reproduce a result.
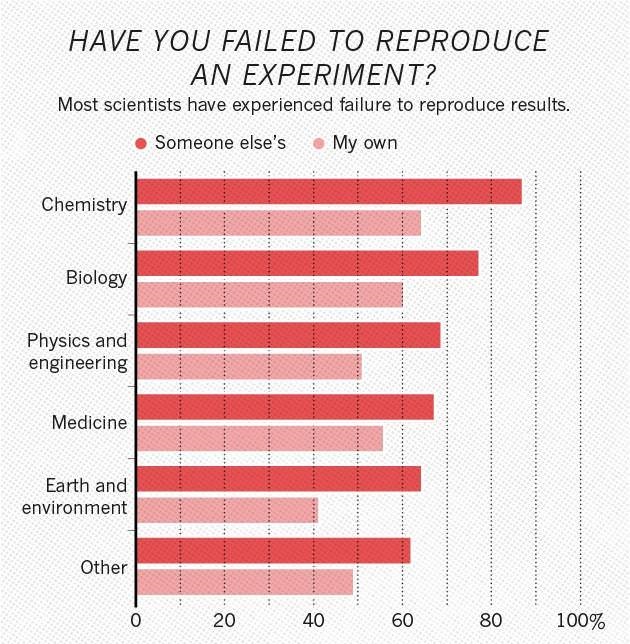
Of the 1576 scientists surveyed, over 70% of scientists surveyed have experienced failure to reproduce other’s results and over 50% have failed to reproduce their own results.
Reminder:
- P-values measure the probability of getting as convincing a result by chance assuming that there is no effect - they range between 0 and 1. The commonly used threshold for a “statistically significant” result is p < 0.05.
- Effect Sizes measure the strength of a relationship between two variables. There are different types of effect size, for example Cohen’s D or the Pearson corellation coefficient.
Why did it take us so long to notice?
Un”FAIR” data and analyses
It used to be harder to share and access data and analyses. FAIR principles describe how data/analyses need to be stored in order for them to be used by others:
- Findable: People need to know the data exists (e.g. link to in your paper)
- Accessible: Data and analysis should be as open as possible and as closed as necessary. They should be available in a format that humans and computers can understand (e.g. downloadable on the internet, and well-documented)
- Interoperable: The data needs to be in a format that people usually use.
- Reusable: Data must be clearly licensed so people know if they’re allowed to reuse them.
If data is messy, unlabelled, in a strange file format, or only on your hard drive, then no one can check if the result is correct.
Why is it happening?
There are lots of points in the process of doing research where something can go wrong, but lots of high profile examples (leading to retractions) come down to:
- Data storage mistakes, e.g. accidentally deleting columns of excel files, or rewriting important values.
- Data analysis implementation mistakes, e.g. accidentally clicking through a GUI in the wrong order, or code not doing what you think it does.
- Questionable research practices, e.g. p-hacking and HARKing
P-hacking
P-hacking is a catch-all term for making p-values appear smaller than they are. It includes practices like:
- Collecting samples until your sample size gives you p < 0.05
- Choosing different statistical tests until you get p<0.05
- Running lots of statistical tests and not correcting for multiple hypotheses
P-curves show evidence that this is occurring in research, particularly when p-values are close to 0.05.
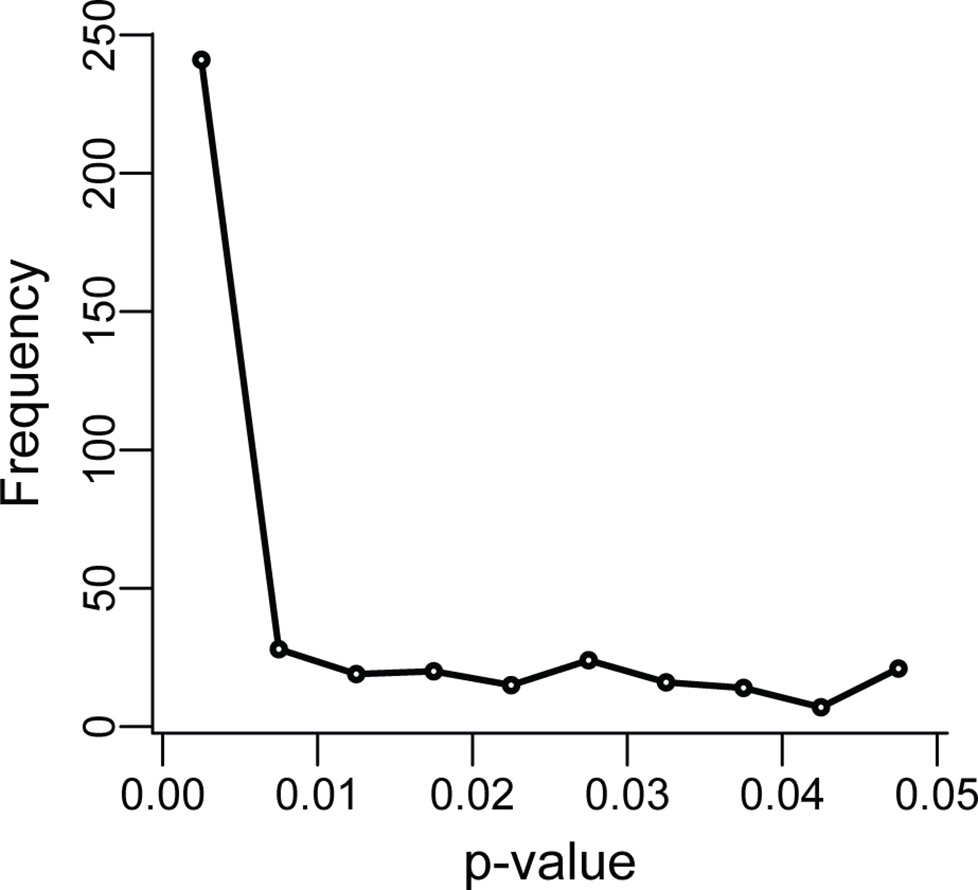
HARKing
HARKing stands for “Hypothesising After Results are Known”.
The xkcd jellybean comic illustrates it well:

Discussion: Barriers to reproducibility in your field.
We’ve mentioned some barriers to reproducibility so far. In small groups, first write down the issues you remember on the paper in front of you in one colour. Then discuss how you think these reproducibility problems mentioned might affect your fields. (10 minutes total)
Solutions
Make data available
By making your data available, you can ensure that you and others will be able to replicate your work. This can involve:
- Making your original data freely available
- Storing your original data in a secure place and only sharing it with people who meet ethical research standards.
- Making anonymised or aggregated data available.
- Synthesising data which is similar to your original data, but does not contain any real subjects, and make that available.
Whatever you make available, it must be well labelled and described if it’s going to be useful for future you, or for others.


Make analysis available
Scripts make analysis available by writing scripts, they:
- Describe exactly what your analysis is and can be shared with others
- Can be written in any programming language (e.g R, Python)
- Always perform in the same order and get the same result
- Those written in non-proprietary software (e.g. R and python, rather than SPSS/Stata) are more accessible.
Literate programming = scripts + describing what’s happening
Ways to do it:
- Comments
- Documentation
- README files
- Notebooks (e.g. RMarkdown, Jupyter)
Much of the time this is carried out in markdown. Markdown is a way of turning simple formatting into html (to be shared on the web). It’s the language of RMarkdown and GitHub.
Version Control
- You will want different versions of your scripts/notebooks.
- Nothing is worse than knowing your program worked earlier, but that it doesn’t now.
- Having files named
analysis_ver32_final_actually_final.Ris not fun and it’s easy to make mistakes. - When you come back to your work later, you won’t be able to remember which is the
for_realsies_final_file.txt - It’s difficult to add new things to your analysis at the same time as having a working version.
Version control is a system for avoiding these problems.

Pre-registration
The first principle is you must not fool yourself — and you are the easiest person to fool - Richard Feynman

If you are doing hypothesis-confirming research, consider pre-registering your analysis is saying what analysis you are going to do in advance, including:
- which variables you are going to look at
- what sample size you will aim for
- what you will exclude from your sample
- what variables you are going to correct for
This prevents you from accidentally trying out more hypothesis than you meant to, and shows other people that you didn’t.
Registered reports
Registered reports are a new model for publishing papers. Instead of applying to journals once you have your results, you apply while after you have made plans for research and analysis, but before you have collected your data.
Extra great for research(ers) because:
- You can publish non-significant results
- We will all be able to benefit from knowing what doesn’t work.

Discussion: how do these core concepts of reproducibility relate to our workflow today?
In small groups, looking at our workflow for today, try to list which of the following reproducibility problems are being prevented during each step of the workflow:
Data storage mistakes (e.g. deleting rows of spreadsheets)
Data analysis mistakes (e.g. you didn’t do what you meant to do)
Questionable research practices (e.g. p-hacking)
Suggestions
- FAIR (Accessible and Reusable) data and code (well-organised)
- Prevents data analysis mistakes
- FAIR (Findable) code
- Prevents questionable research practices
- FAIR (Accessible and Reusable) code
- Prevents data analysis mistakes 7 + 8. FAIR (Findable and Accessible) results, prevents data analysis mistakes.
Five selfish reasons to work reproducibly
We do want to trust science, and to do good work, and to not waste people’s time, and all of the other selfless reasons to work reproducibly, but there are also good selfish reasons to do so:
- Reproducibility helps to avoid disaster
- Reproducibility makes it easier to write papers/your thesis
- Reproducibility helps reviewers see it your way
- Reproducibility enables continuity of your work
- Reproducibility helps to build your reputation
These reasons are taken from Florian Markowetz’s paper.
Additional benefits of working “Openly”
In addition to making sure that science is working (being reproducible), this workflow is about working Openly. What I mean by that in this context, is sharing your plans, code, results, etc, as you go through the process, and not just at the end.
So, on top of the selfish benefits of working reproducibly working Openly is also beneficial for:
- Your citation count (papers with preprints get more citations)
- Your networks (other people will see your work more)
- (Anecdotally) your enjoyment of research: it is way less lonely, and you get the dopamine rush of finishing something and getting it out there way more often.
Key Points
The results of published research don’t always reproduce.
Make your data and analysis FAIR (Findable, Accessible, Interoperable and Reusable); as apen as possible, and as closed as necessary
Ask for help if you need statistics or software support: research software engineers, your statistics department.